Netty学习指北03
ByteBuf类–Netty的数据容器
因为所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的. Netty的ByteBuf实现满足并超越了这些需求.
1.ByteBuf的API
Netty的数据处理API通过两个组件暴露–>abstract class ByteBuf和interface ByteBufHolder.
下面是一些ByteBuf的优点:
- 它可以被用户自定义的缓冲区类型扩展
- 通过内置的复合型缓冲区类型实现了透明的零拷贝
- 容量可以按需增长(类似于JDK的StringBuilder)
- 在读和写两种模式之间切换不需要调用ByteBuffer的flip()方法
- 读和写使用了不同的索引
- 支持方法的链式调用
- 支持引用计数
- 支持池化
2.ByteBuf是如何工作的
ByteBuf维护了两个不同的索引:一个用于读取,一个用于写入.
当你从ByteBuf读取时,它的readerIndex将会被递增已被读取的字节数.
同样的,当你写入ByteBuf时,它的writeIndex也会被递增.
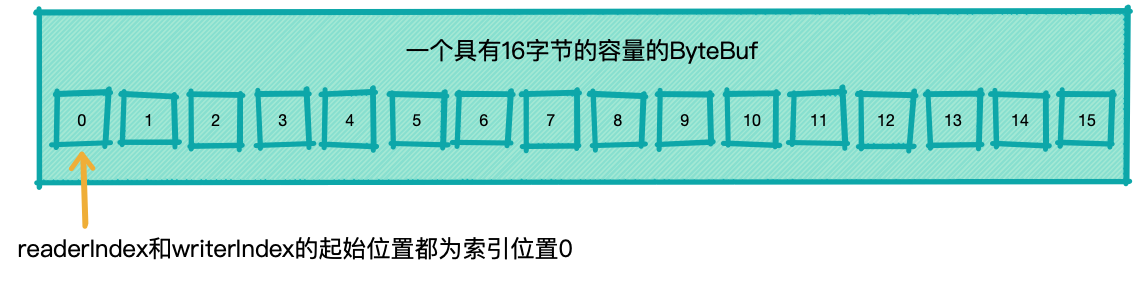
如果打算读取字节直到readerIndex达到和writerIndex同样的值时会发生什么?
在那时,你将会达到”可以读取的”数据末尾.就如同试图读取超出数组末尾的数据一样,
试图读取超过该点的数据将会触发一个IndexOutOfBoundsException.
名称以read或者write开头的ByteBuf方法,将会推进其索引,而名称为set或get开头的操作则不会.
后面的这些方法将在作为一个参数传入的一个相对索引上执行操作.
可以指定ByteBuf的最大容量.试图移动写索引(即writerIndex)超过这个值将会触发一个异常.
(默认的限制是Integer.MAX_VALUE)
ByteBuf的使用模式
1.堆缓冲区
最常用的ByteBuf模式是将数据存储在JVM对空间中.这种模式被称为支撑数组(backing array), 它能在没有使用池化的情况下提供快速的分配和释放.这种方式非常适合于有遗留数据需要处理的情况.
ByteBuf heapBuf = ...;
// 检查ByteBuf是否有一个支撑数组
if(heapBuf.hasArray()){
// 如果有,获取对该数组的引用
byte[] array = heapBuf.array();
// 计算第一个字节的偏移量
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
// 获取可读字节数
int length = heapBuf.readableBytes();
// 使用数组,偏移量,长度作为参数调用方法.
handleArray(array,offset,length);
}
2.直接缓冲区
直接缓冲区是另外一种ByteBuf模式.我们期望用于对象创建的内存分配永远都来自于堆中, 但这并不是必须的—NIO在JDK1.4中引入的ByteBuffer类允许JVM实现通过本地调用来分配内存. 这主要是为了避免在每次调用本地I/O操作之前(或之后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区复制到缓冲区)
ByteBuffer的JavaDoc明确指出:直接缓冲区的内容将驻留在常规的会被来及回收的堆之外 这也就解释了为何直接缓冲区对于网络数据传输是理想的选择.如果你的数据包含在堆上分配的缓冲区中, 那么事实上,在荣国套接字发送它之前,JVM将会在内部把,你的缓冲区复制到一个直接缓冲区中.
直接缓冲区的主要缺点是,相对于基于堆的缓冲区,它们的分配和释放都比较昂贵.如果你正在处理遗留代码, 你也可能会遇到另外一个缺点:因为数据不是在堆上,所以你不得不进行一次复制.
ByteBuf directBuf = ...;
// 检测ByteBuf是否由数组支撑
if (!directBuf.hasArray()){
// 获取可读字节数
int length = directBuf.readableBytes();
// 分配一个新的数组来保存具有该长度字节的数据
byte[] array = new byte[length];
// 将字节复制到该数组
directBuf.getBytes(directBuf.readerIndex(),array);
// 将数组,偏移量,长度作为参数调用业务方法
handle(array,0,length);
}
与使用支撑数组相对,这涉及的工作更多.因此,如果事先知道容器中的数据将会作为数组来访问,你可能更愿意使用堆内存.
3.复合缓冲区
复合缓冲区为多个ByteBuf提供一个聚合视图.在这里你可以根据需要添加或者删除ByteBuf实例, 这是一个JDK的ByteBuf完全缺失的特征.
Netty通过一个ByteBuf子类–CompositeByteBuf–实现了这个模式,
它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示.
CompositeByteBuf byteBufs = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...;
ByteBuf bodyBuf = ...;
// 将ByteBuf追加到CompositeByteBuf
byteBufs.addComponents(headerBuf,bodyBuf);
// 删除位于索引0的ByteBuf
byteBufs.removeComponent(0);
// 遍历所有的ByteBuf实例
for (ByteBuf byteBuf : byteBufs) {
System.out.println(byteBuf.toString());
}
CompositeByteBuf byteBufs = Unpooled.compositeBuffer();
int length = byteBufs.readableBytes();
byte[] array = new byte[length];
// 将字节读到该数组中
byteBufs.getBytes(byteBufs.readerIndex(),array);
// 使用偏移量和长度作为参数使用该数组
handleArray(array,0,array.length);
Reference
- Netty实战
- netty.io
- Netty 4.x User Guide
- Netty用户指南
转载
本文遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。