前言
写这篇文章的契机是工作中遇到的一个场景。生产环境中有一个数据量巨大(10亿级)且已经用Shardingjdbc做了分表的多表数据集。 分表逻辑是这样的,每天一张表,当天产生的数据录入当天的表内(例:2020年6月5日的数据录入到table_20200605表中)。 其中有一个查询需要做多天数据的聚合,之前的方案是通过Shardingjdbc做多表聚合,数据量大了之后,效率极低, 低到已经无法使用的程度,只能暂时在业务上限制,对多只能跨两张表查询。
经过了一段时间的技术选型,我们决定核心业务依然依赖MySQL,但是列表查询使用ElasticSearch作为查询组件。 这时又产生了一个新的问题,要如何从MySQL把数据实时同步到ES?
方案对比
在查阅了大量资料后,初步选择确定在了elasticsearch-jdbc,go-mysql-elasticsearch,logstash-input-jdbc以及canal
这四个同步方案。我对这几个工具做了横向对比。
| 插件名称 | 优点 | 缺点 |
|---|---|---|
| elasticsearch-jdbc | 泛用度比较高,社区活跃 | 不能实现同步删除操作.通过查询做同步,对MySQL吞吐有影响 |
| go-mysql-elasticsearch | 通过binlog做同步,能同步增删改查 | 经测试同步效率较低 |
| logstash-input-jdbc | 为logstash的一部分,易用性较高 | 不能实现同步删除操作.通过查询做同步,对MySQL吞吐有影响 |
| canal | 通过binlog做同步,能实现增删改查,效率高,功能多样 | 学习成本较高,在没有技术积累时无法快速投入使用,顺序消费场景下,消费者横向扩展比较麻烦 |
最终,我们确定了使用canal作为MySQL增量数据的同步方案。
canal
canal是什么
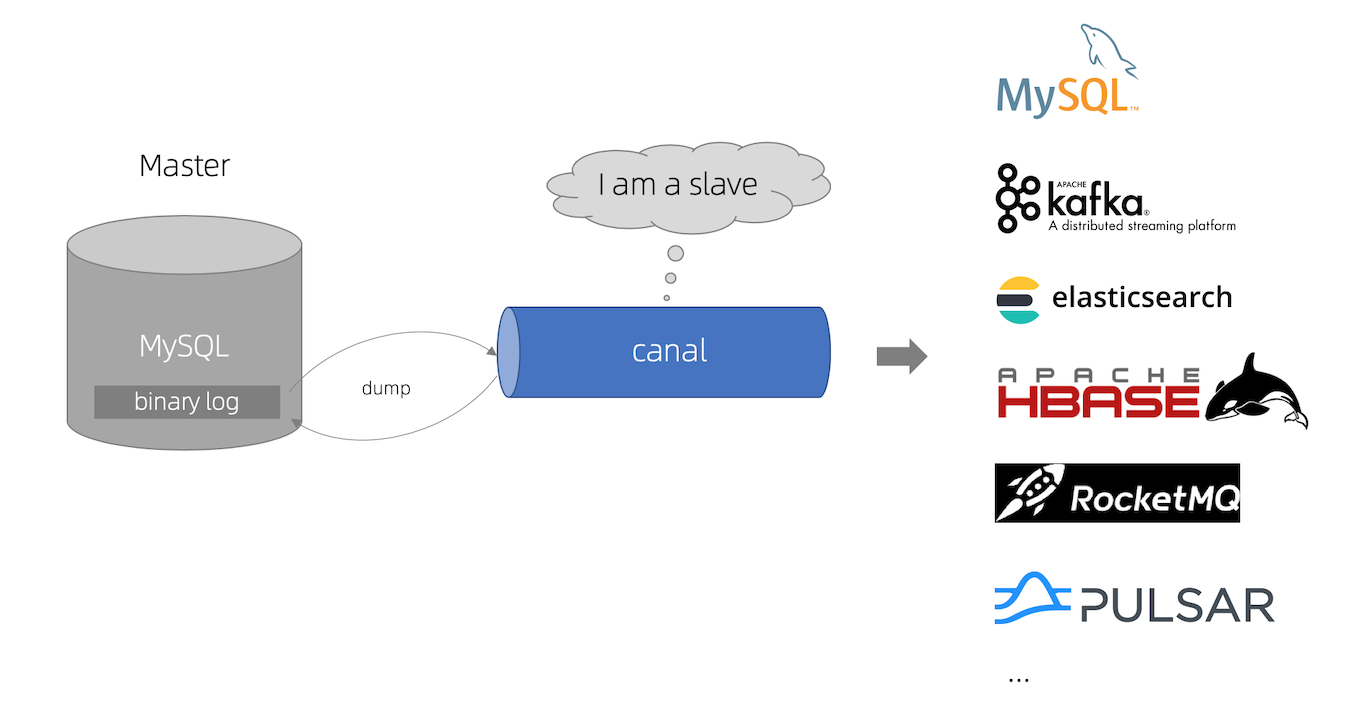
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始, 业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
canal工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) canal 解析 binary log 对象(原始为 byte 流)
canal的重要版本
截止到我写这篇文章的时候,canal的最新稳定版是1.1.4,还无法支撑MySQL8.0。在已经发布的1.1.5-alpha-1版本中, canal已经可以支持拉取MySQL8.0的binlog,canal-adapter也支持了对ES7.X版本进行同步,所以未来可期。
canal的组件
canal-server与canal-client
核心组件有两个,canal-server和canal-client(以下简称server和client)。server伪装成MySQL的slave,拉取binlog, 经过处理后,发送给client,在client接收到已经结构化的数据后,可以根据自己的需求对数据做处理, 不管是要同步到ES,HBase,Hive都是可以的。
canal-adapter
client需要使用者自己实现,虽然官方提供了例子,但其实大家的需求是大同小异的,为了避免重复造轮子, canal还提供了一个官方实现功能极强的client,名字叫canal-adapter(以下简称adapter)。canal配合adapter基本可以实现大部分非定制化增量数据同步。 最新版的adapter内部还使用了SPI这种黑魔法,源码读起来可能会很迷茫。还有消息顺序消费的方案也做的比较有意思。 这里就不展开了,后面会专门写一篇文章来分析这部分。
同步方案
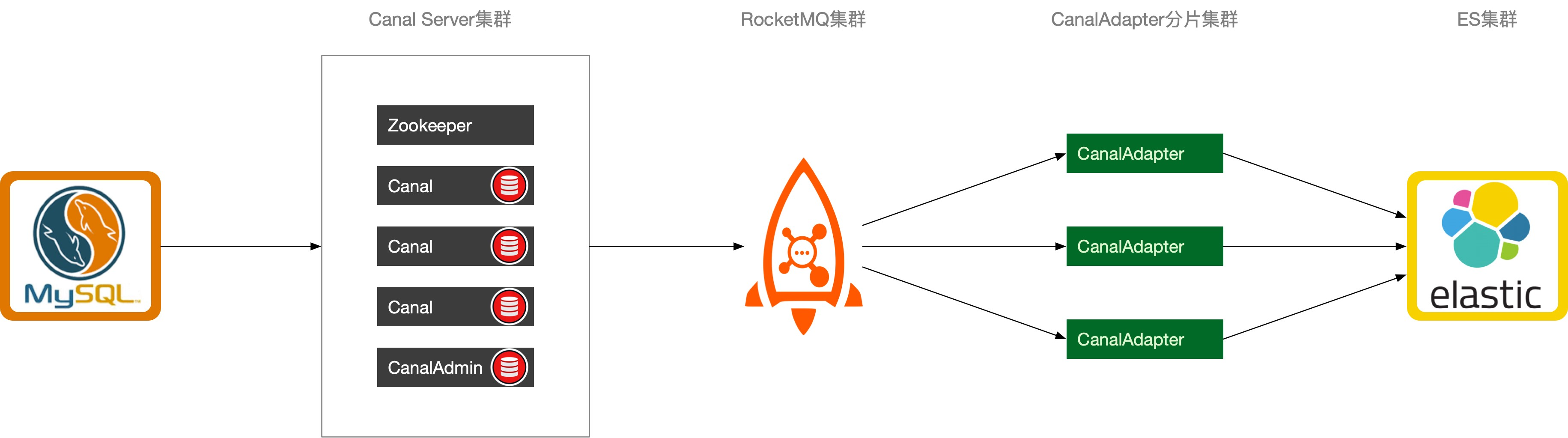
在这不详细讨论canal的集群方式,canal-wiki已经写的很清晰了。 这里着重讨论一下canal-adapter的分片,这部分wiki写的不是很清楚。adapter共有四种模式,tpc,rocketMQ,kafka,rabbitMQ。 除开tcp直连server外,剩下三种都使用MQ做中转,做到了server和adapter解耦。
当然,在上面的那种模式下,如果某台adapter宕机了以后,其他的adapter是不能把发给它的消息给接过去的,因为数据是做了分片或者映射的。 在使用了MQ做中转的情况下,adapter可以根据topic做分片,每个adapter仅接收对应的一个或几个topic的消息,然后做顺序处理。 canal当然也支持按正则映射或者hash的方式发送消息到不同的topic。
canal-adapter如何横向扩展
根据库名或表名路由最细粒度的使用是一个表对应一个topic,虽然有根据pk路由,但是如果有pk变更, pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题。 经过测试,tcp模式的adapter的tps极限大概在6000左右,mq模式的adapter其中一个topic的tps极限在3000出头, 如果MySQL某张表的tps一直处于大于3000的情况,那只有使用pk分区路由才能解决。 不过MySQL的某一张表的tps一直大于3000的情况并不常见,所以这里只讨论根据一个表对应一个topic的情况(多topic单分区)。
补充:这里多topic多分区和多topic单分区,在一个表对应一个topic,不使用pk做hash分区并且在顺序消费下性能其实没有什么区别, 分区其实指的就是RocketMQ中的queue,Kafka中的partition。其中topic和queue(partition)是一对多的关系,其中每个queue(partition)自身是可以保证有序的。
如果MySQL新增了数据库表,那么表就会路由到一个新的topic中,如果这张表的tps不高,那么就可以直接修改某台adapter的配置文件application.yml, 增加一个instance,topic就是新增的表名,再增加一个对应数据源的mapping映射,然后重启adapter,就搞定了。 如果这张表的tps特别高,达到了2000+,那么就可以给这个表对应topic搞一个单独的adapter来专门监听这个topic的内容。
如果正则配置得当的情况下,server是不需要重启的,这样就保证了用户使用的过程中是无感知的。
mq顺序性问题
canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),
如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,
但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
为什么MySQL只能使用row模式才可以同步
我在刚接触到adapter的时候有一个疑问,为什么canal只能同步row模式的binlog? MySQL的binlog是逻辑日志,也就是消费端是要保证绝对有序,才能正确的消费,否则就会产生数据不一致的情况。 首先,MySQL的binlog总共有三种模式,row,statement,mixed。
在row模式下,binlog中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。
statement模式由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息, 以保证所有语句能在slave得到和在master端执行时候相同的结果。mixed模式是row模式和statement模式的混合,我们暂且不讨论。 使用statement模式会大大增加解析的复杂度,试想你写了一条特别复杂的删除语句,可能你要同步的目标数据源根本就没有这么强的聚合功能,这时就无计可施了。
总结
canal-server是将自己伪装成MySQL的slave,从master拉取binlog,结构化解析的工具。
canal-client是将canal-server拉取到binlog进行解析,深度定制化(因为要自己写)。
canal-adapter是canal官方提供的通用client解决方案,可以解决大部分的增量数据迁移场景。
Reference
转载
本文遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。