Netty学习指北04
ByteBuf提供了许多超出基本读,写操作的方法用于修改它的数据.
字节级操作
随机访问索引
如同普通的Java字节数组中一样,ByteBuf的索引是从零开始的:第一个字节的索引是0,
最后一个字节的索引总是,capacity() -1.对存储机制的封装使得遍历ByteBuf的内容非常简单.
ByteBuf buffer = ...;
for(int i = 0; i < buffer.capacity(); i++){
byte b = buffer.getByte(i);
System.out.println((char)b);
}
使用那些需要一个索引值得参数的方法的其中之一来访问数据既不会改变readerIndex也不会改变writerIndex.
如果有需要,也可以通过readerIndex(index)或者writerIndex(index)来手动移动这两者.
顺序访问索引
虽然ByteBuf同时具有读索引和写索引,但是JDK的ByteBuffer却只有一个索引,
这也就是就是为什么必须调用flip()方法在读模式和写模式之间进行切换的原因.
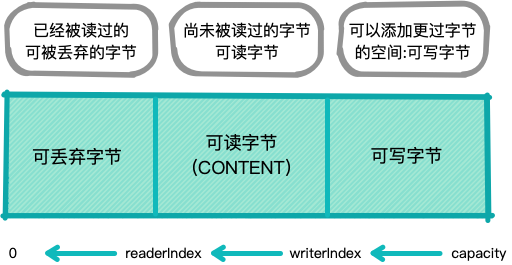
可丢弃字节
被标记为可丢弃字节的分段包含了已经被读过的字节.通过调用discardReadBytes()方法,
可以丢弃它们并回收空间.这个分段的初始化大小为0,存储在readerIndex中,
会随着read操作的执行而增加(get*操作不会移动readerIndex)
执行discardReadBytes()方法后的结果.
可以看到,可丢弃字节分段中的空白已经变成可写的了.
注意:在调用discardReadBytes()之后对可写分段没有任何保证
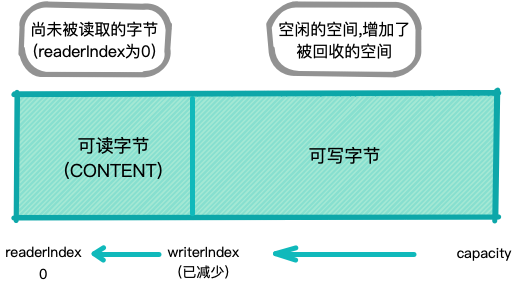
虽然你可能会倾向于频繁的调用discardReadBytes()方法以确保可写分段的最大化, 但这极有可能会导致内存复制,因为可读字节必须被移动到缓冲区开始的位置. 所以建议只有在真正需要的时候才这样做.
可读字节
ByteBuf的可读字节分段存储了实际数据.新分配的,包装的或者复制的缓冲区的默认的readerIndex值为0.
任何名称以read或者skip开头的操作都将检索或者跳过位于当前readerIndex的数据,
兵器且将它增加已读的字节数.
如果被调用的方法需要一个ByteBuf参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的writeIndex也将被增加
例如: readBytes(ByteBuf dest);
如果尝试在缓冲区的可读字节数耗尽时从中读取数据,那么将引发一个IndexOutOfBoundsException异常.
ByteBuf buffer = ...;
while(buffer.isReadable()){
system.out.println(buffer.readByte());
}
可写字节
可写字节分段是指一个拥有未定义内容的,写入就绪的内存区域.新分配的缓冲区的writerIndex的默认值为0.
任何名称以write开头的操作都将从当前的writerIndex处开始写数据,并将它增加已经写入数据的字节数.
如果写操作的目标也是ByteBuf,并且没有指定源索引的值,则缓冲区的readerIndex也同样会被增加同样的大小.
索引管理
可以通过调用markReaderIndex(),markWriterIndex(),resetWriterIndex(),resetReaderIndex()
来标记和重置ByteBuf的readerIndex,writerIndex.这些和InputStream上的调用类似,只是没有readLimit参数来指定什么时候失效.
可以通过调用readerIndex(int) ,writerIndex(int) 来讲索引移动到指定位置.
可以通过调用clear()方法来讲readerIndex和writerIndex都设置为0.而且这并不会清除内存中的内容.
查找操作
在ByteBuf中有多种可以用来确定指定值的索引的方法.最简单的是使用indexOf()方法.
如果是比较复杂的查找可以通过那些需要一个ByteBufProcessor作为参数的方法达成.这个接口只定义了一个方法:
boolean process(byte value)
它将检查输入值是否是正在查找的值.
ByteBufProcessor针对一些常见的值定义了许多便利的方法.
例如你的应用需要和所有的包含有以NULL为结尾的内容的Flash套接字集成.只需要调用:
forEachByte(ByteBufProcessor.FIND_NULL)
将简单高效地消费Flash数据,因为在处理期间只会执行较少的边界检查.
Reference
- Netty实战
- netty.io
- Netty 4.x User Guide
- Netty用户指南
转载
本文遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。